Stream processing
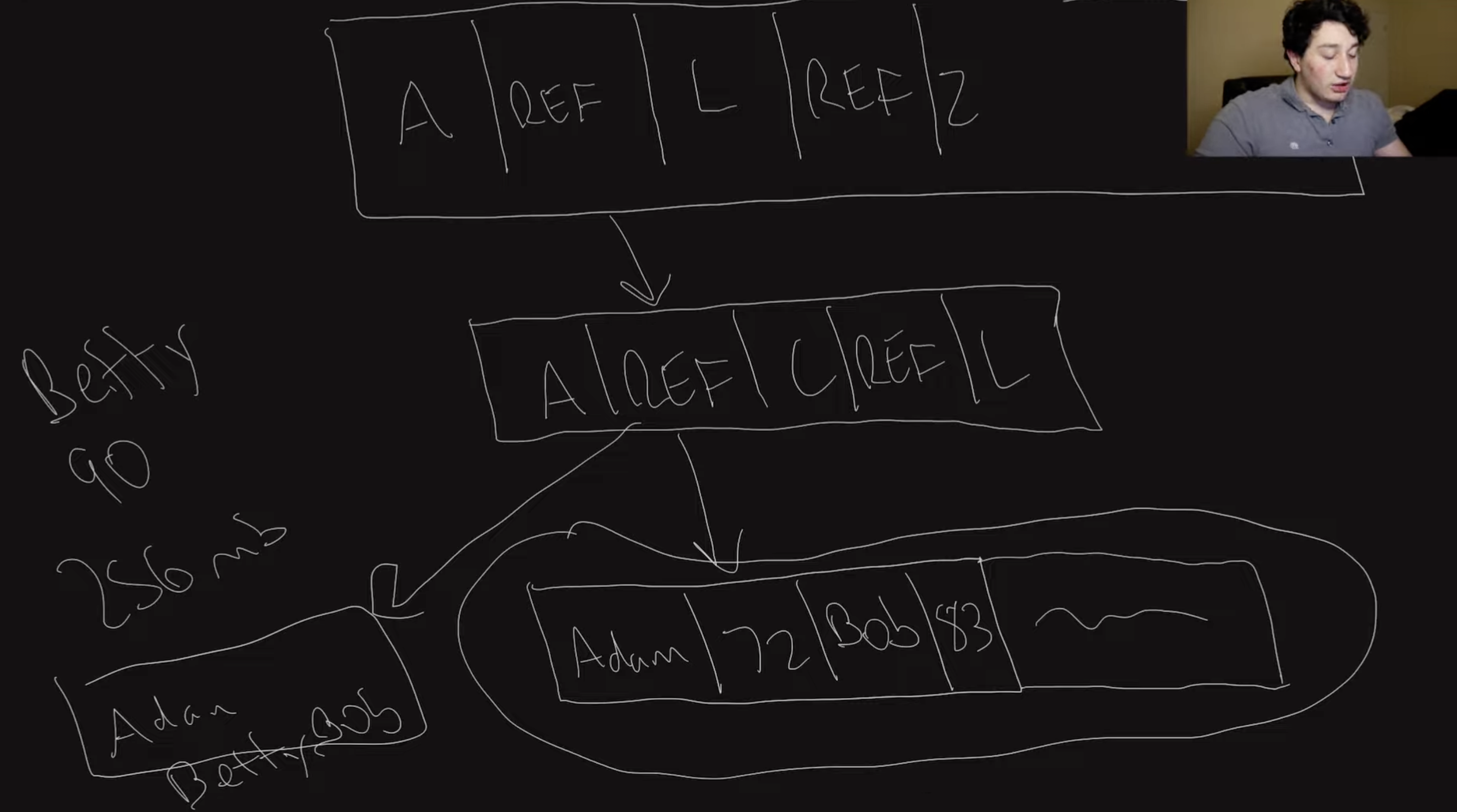
B-tree
B-tree is stored on disk, each node has fixed size. It is log(N) fast to read. When writing if there is a a space, then just create a new node and point to the new node. When there are no space, then split the node into 2 nodes.
If B-tree dies, you can have write-ahead-log (WAL).
B-trees are good for range queries.
It’s self-balancing, so it’s good for write-heavy workloads.
MapReduce vs Spark
- Chained jobs don’t know about each other
- Each job needs mapper and reducer - unnecessary sorting
- Tons of disk usage (intermediate data is also stored on disk).
Spark writes only input and output to disk the rest is in Resilient Distributed Dataset (RDD) in memory. As for fault tolerance, there is narrow dependency (all computations on one node) and wide dependency (computation on multiple nodes). If a node fails, then the computation is done on another node (occasional write checkpoint to disk).
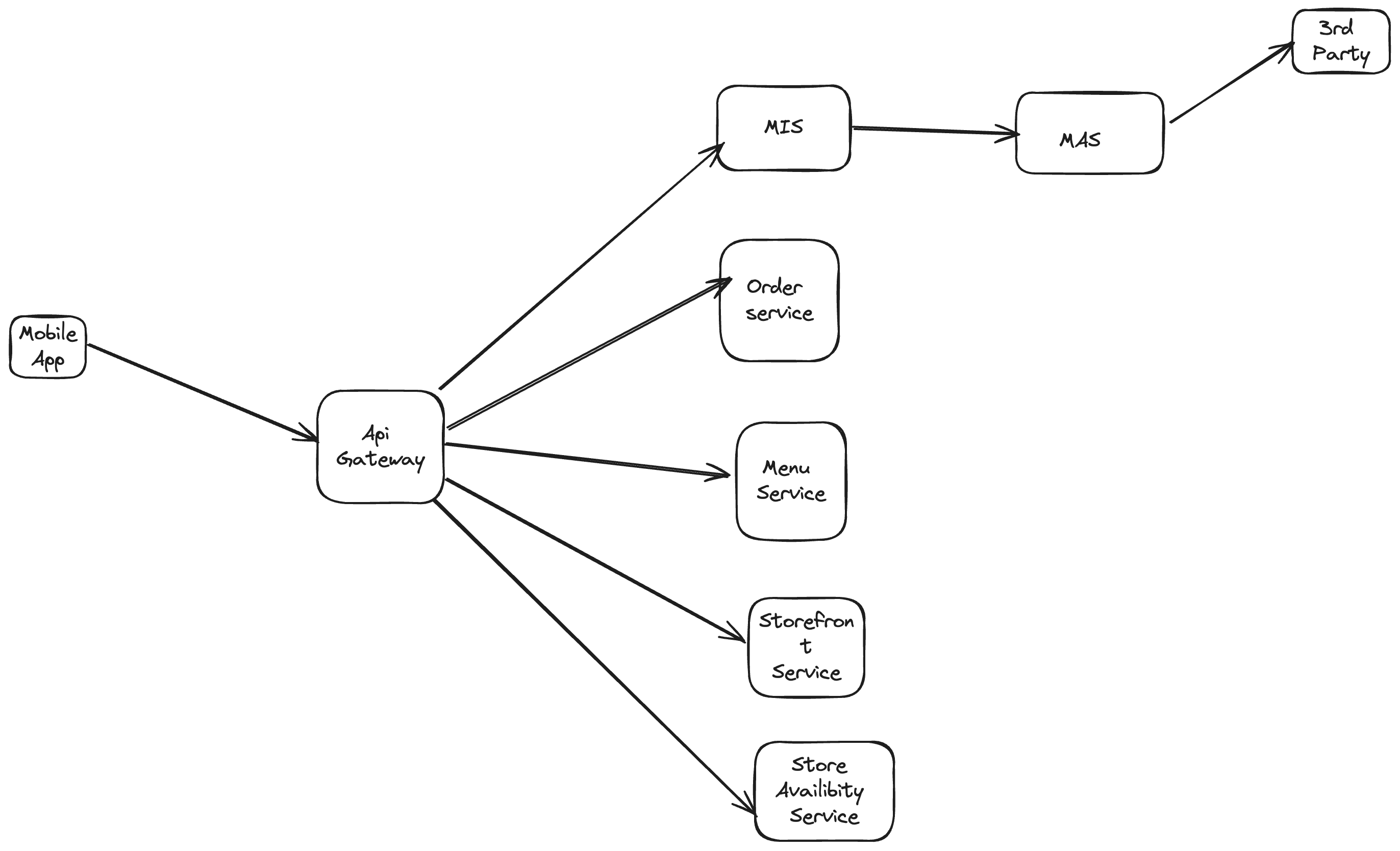
Doordash
API gateway server code is written in Kotlin
MIS - merchant information system MAS - merchant agent service gRPC - remote procedure call framework - one step above HTTP Protobuf - protocol buffer - language agnostic data interchange format spango jwt token is given and API gateway check again the token Order service - Cassandra, write heavy, LSM tree is super fast (Red black tree) when it accumulates RAM memory it writes to disk via S-Table (immutable read only on disk).
Indexed BTree - good for reading, write for disk Single tree replication 256Gb RAM je max
when user adds to cart, they are given session_id - unique identifier for the users session when user is ready to checkout, it clicks checkout - calls create cart from shopping session payment goes to Stripe - it returns stripe token
Google Food Ordering Kafka, Flink, Cassandra, Redis
Jordan has no life - Uber - https://www.youtube.com/@jordanhasnolife5163/videos